介绍Spark SQL中的基本重要概念
DataType
数据类型主要用来表示数据表中存储的列信息。如下图所示,Spark sql中的数据类型都继承自DataType。包括简单的整数、浮点数、字符串,以及复杂的嵌套结构。常用的复合数据类型有数组类型ArrayType、字典类型MapType和结构体类型StructType。其中,数组类型中要求数组元素类型一致,字典类型中既要求所有 key 的类型一致,也要求所有的 value 类型一致。
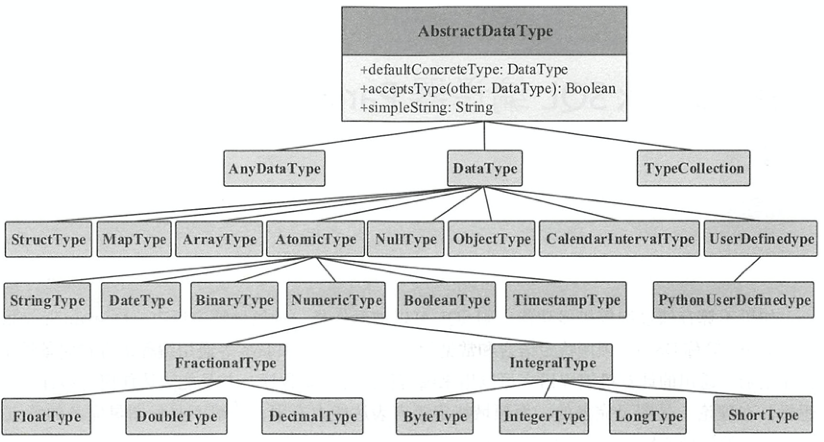
StructField表示结构体中的类型,共定义了4个属性,字段名称name、数据类型dataType、是否允许为空nullable、元数据metadata。StructType通过Array[StructField]类型的fields参数保存了零到多个StructField
lnternalRow
抽象类lnternalRow表示关系表的一行数据,每一列都是Catalyst内部定义的数据类型。继承了SpecializedGetters接口,里面定义了从下标取出某个类型元素的抽象方法。lnternalRow中定义了通过下标来操作列元素的抽象方法
def setNullAt(i: Int): Unit
def update(i: Int, value: Any): Unit
def setBoolean(i: Int, value: Boolean): Unit = update(i, value)
...
// SpecializedGetters.java
boolean getBoolean(int ordinal);
...
抽象类lnternalRow有以下实现的子类
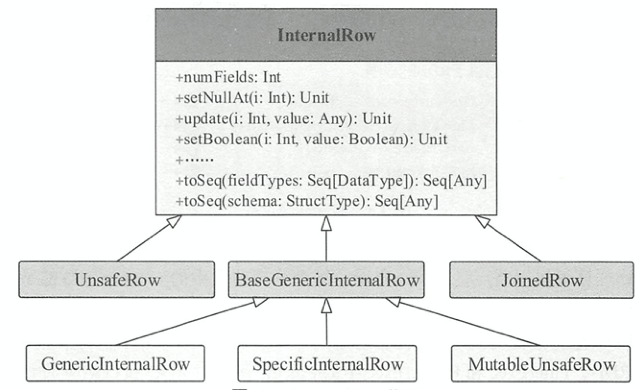
JoinedRow
由两个InternalRow构造,用于join操作,直接将两个InternalRow拼接起来
override def numFields: Int = row1.numFields + row2.numFields
override def get(i: Int, dt: DataType): AnyRef =
if (i < row1.numFields) row1.get(i, dt) else row2.get(i - row1.numFields, dt)
override def isNullAt(i: Int): Boolean =
if (i < row1.numFields) row1.isNullAt(i) else row2.isNullAt(i - row1.numFields)
UnsafeRow
使用堆外内存,避免了 JVM 中垃圾回收的代价。此外,UnsafeRow对行数据进行了特定的编码,使得存储更加高效。
BaseGenericlnternalRow
特质BaseGenericlnternalRow应用了模板方法设计模式,实现了 SpecializedGetters接口中定义的所有get类型方法,但是暴露出未实现的genericGet()由子类实现。
protected def genericGet(ordinal: Int): Any
private def getAs[T](ordinal: Int) = genericGet(ordinal).asInstanceOf[T]
override def isNullAt(ordinal: Int): Boolean = getAs[AnyRef](ordinal) eq null
override def get(ordinal: Int, dataType: DataType): AnyRef = getAs(ordinal)
override def getBoolean(ordinal: Int): Boolean = getAs(ordinal)
...
GenericlnternalRow
lnternalRow的一种实现,使用Array[Any]数组作为基础存储,并且构造参数数组是非拷贝的,因此一旦创建就不允许通过set操作进行改变
// 注意values使用val修饰
class GenericInternalRow(val values: Array[Any]) extends BaseGenericInternalRow {
/** No-arg constructor for serialization. */
protected def this() = this(null)
def this(size: Int) = this(new Array[Any](size))
override protected def genericGet(ordinal: Int) = values(ordinal)
override def toSeq(fieldTypes: Seq[DataType]): Seq[Any] = values.clone()
override def numFields: Int = values.length
override def setNullAt(i: Int): Unit = { values(i) = null}
override def update(i: Int, value: Any): Unit = { values(i) = value }
}
SpecificinternalRow
相对于GenericlnternalRow来说,使用Array[MutableValue]为构造数组,允许通过set操作改变。
MutableValue类型是对基本类型的包装,当值改变时也可以重用,减少垃圾回收
abstract class MutableValue extends Serializable {
var isNull: Boolean = true
def boxed: Any
def update(v: Any): Unit
def copy(): MutableValue
}
final class MutableInt extends MutableValue {
var value: Int = 0
override def boxed: Any = if (isNull) null else value
override def update(v: Any): Unit = {
isNull = false
value = v.asInstanceOf[Int]
}
override def copy(): MutableInt = {
val newCopy = new MutableInt
newCopy.isNull = isNull
newCopy.value = value
newCopy
}
}
MutableUnsafeRow
和UnsafeRow相关,用来支持对特定的列数据进行修改
TreeNode
抽象类TreeNode是物理计划和逻辑计划中所有树结构的基类,通过Seq[BaseType]类型的children变量来储存子结点,通过origin属性来存储当前结点对应在SQL语句的行和起始位置
静态类CurrentOrigin为TreeNode提供当前结点的数据源位置,如根据树结点定位SQL语句的行和起始位置
case class Origin(
line: Option[Int] = None,
startPosition: Option[Int] = None)
/**
* Provides a location for TreeNodes to ask about the context of their origin. For example, which
* line of code is currently being parsed.
*/
object CurrentOrigin {
private val value = new ThreadLocal[Origin]() {
override def initialValue: Origin = Origin()
}
def get: Origin = value.get()
def set(o: Origin): Unit = value.set(o)
def reset(): Unit = value.set(Origin())
def setPosition(line: Int, start: Int): Unit = {
value.set(
value.get.copy(line = Some(line), startPosition = Some(start)))
}
def withOrigin[A](o: Origin)(f: => A): A = {
set(o)
val ret = try f finally { reset() }
ret
}
}
继承自product特质,但是并没有实现其抽象方法,因为其最终子类是case class,自动实现了product中的抽象方法,用于返回子case class中的样例属性,其children属性内容与样例属性是一致的
除了常见的集合方法外,如下所示TreeNode中还实现的针对树的一些遍历方法
collectLeaves(): 获取当前TreeNode所有叶子节点collectFirst(): 先序遍历所有节点并返回第一个满足条件的节点withNewChildren(): 将当前节点的子节点替换为新的子节点transformDown(): 用先序遍历方式将规则作用于所有节点transformUp(): 用后序遍历方式将规则作用于所有节点transformChildren(): 递归地将规则作用到所有子节点
如下图所示,抽象类TreeNode有以下继承关系
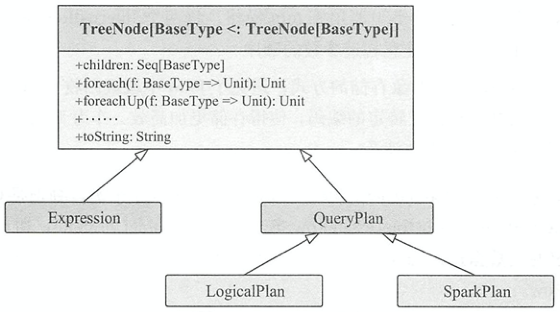
Expression
抽象类TreeNode的子类。表达式一般指的是不需要触发执行引擎而能够直接进行计算的单元,例如加减乘除四则运算、逻辑操作、转换操作、过滤操作等
基本操作
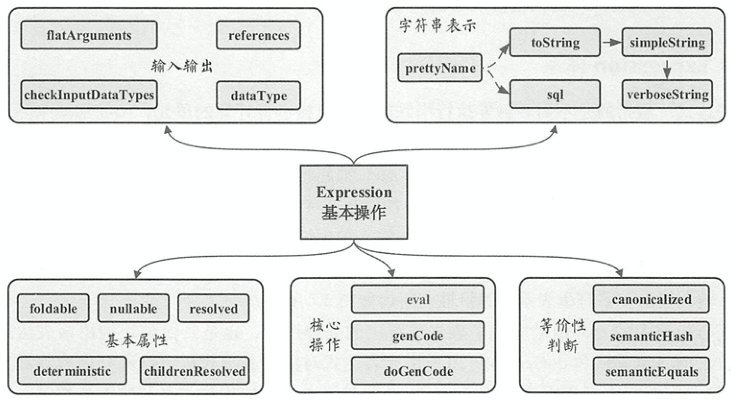
如图所示,除了TreeNode内的一些方法外,主要定义了基本属性、核心操作、输入输出、字符串表示和等价性判断这5个基本操作
- 输入输出
dataType(): 表达式返回类型checkInputDataTypes(): 检查输入数量类型是否合法references():返回AttributeSet该表达式中会涉及的属性值,默认为所有子节点中属性值的集合
- 核心操作
eval(): 实现了表达式对应的处理逻辑,也是其他模块调用该表达式的主要接口genCode(),doGenCode(): 生成表达式对应的Java代码
- 基本属性
foldable: 返回表达式能否在查询执行之前直接静态计算,即在算子树中可以直接预先处理(折叠)。当表达式为Literal类型或者子表达式中foldable()都 true时,此表达式的foldable()返回truedeterministic: 用来标记表达式是否为确定性的,即每次执行eval()函数的输出是否都相同。该属性对于算子树优化中判断谓词能否下推等很有必要childrenResolved,resolved: 是否解析了所有的占位符,resolved调用了childrenResolved()并且做了输入类型检查nullable: 用来标记表达式是否可能输出Null值, 一般在genCode()生成的Java代码中对null值进行判断
- 等价性判断
canonicalized: 经过规范化处理后的表达式。规范化处理会在确保输出结果相同的前提下通过一些规则对表达式进行重写semanticEquals(): 判断两个表达式在语义上是否等价。默认的判断条件是两个表达式都是确定性的且两个表达式经过规范化处理后相同semanticHash(): 规范表达式的哈希值
- 字符串表示: 输出表达式信息
继承体系
Expression涉及范围广且数目庞大,相关的类或接口将近 300 个,下面列举一些常用的接口
Nondeterministic: 具有不确定性的表达式接口,deterministic和foldable属性都默认返回false ,典型的实现包括MonotonicallyincreasingID、Rand和Randn等Unevaluable: 非可执行的表达式接口,调用eval()函数会抛出异常。该接口主要用于生命周期不超过逻辑计划解析和优化阶段的表达式CodegenFallback: 不支持代码生成的表达式接口LeafExpression: 叶节点类型的表达式抽象类UnaryExpression: 一元表达式抽象类,只含有一个子节点BinaryExpression: 二元表达式抽象类,包含两个子节点TernaryExpression: 三元表达式抽象类,包含 3 个子节点
下面列举一下常用的实现样例类
- 单值表达式
UnresolvedStar: 代表通配符*,target代表了要拓展的表名或者结构体名case class UnresolvedStar(target: Option[Seq[String]]) extends Star with UnevaluableUnresolvedAttribute: 代表未解析的字段表达式,nameParts代表列名如name,t1.name([t1, name])case class UnresolvedAttribute(nameParts: Seq[String]) extends Attribute with UnevaluableLiteral: 代表常量类型表达式如整数型,字符串型或其他数值型的表达式case class Literal (value: Any, dataType: DataType) extends LeafExpressionUnresolvedFunction: 代表函数,Spark SQL会根据函数名称,在注册中心找到对应的函数case class UnresolvedFunction( name: FunctionIdentifier, // 函数名称 children: Seq[Expression], // 函数参数 isDistinct: Boolean) // 参数是否有 distinct 关键字 extends Expression with UnevaluableAlias: 代表别名,name代表别名的名字,child表示别名的实际表达式case class Alias(child: Expression, name: String)( val exprId: ExprId = NamedExpression.newExprId, val qualifier: Seq[String] = Seq.empty, val explicitMetadata: Option[Metadata] = None) extends UnaryExpression with NamedExpression
数值运算:
Add,Subtract,Multiply,Divide,Remainder(%)// 先计算出左右子表达式的值, 在调用子类实现的nullSafeEval()方法进行计算 // BinaryExpression override def eval(input: InternalRow): Any = { val value1 = left.eval(input) if (value1 == null) { null } else { val value2 = right.eval(input) if (value2 == null) { null } else { nullSafeEval(value1, value2) } } }逻辑表达式,该表达式返回布尔类型
数值比较:
EqualTo,LessThan,GreaterThan…,具体计算实现方式与数值运算类似逻辑运算:
And,Or,Not,下面分析一下And的计算逻辑override def eval(input: InternalRow): Any = { val input1 = left.eval(input) // 若左表达式false, 则不用计算右表达式, and的短路特性 if (input1 == false) { false } else { val input2 = right.eval(input) if (input2 == false) { false } else { if (input1 != null && input2 != null) { true } else { null } } } }
REFERENCE
- Spark SQL内核剖析
- Spark Sql 表达式介绍——zhmin
文档信息
- 本文作者:wzx
- 本文链接:https://wzx140.github.io//2020/10/19/spark-sql-structure/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)